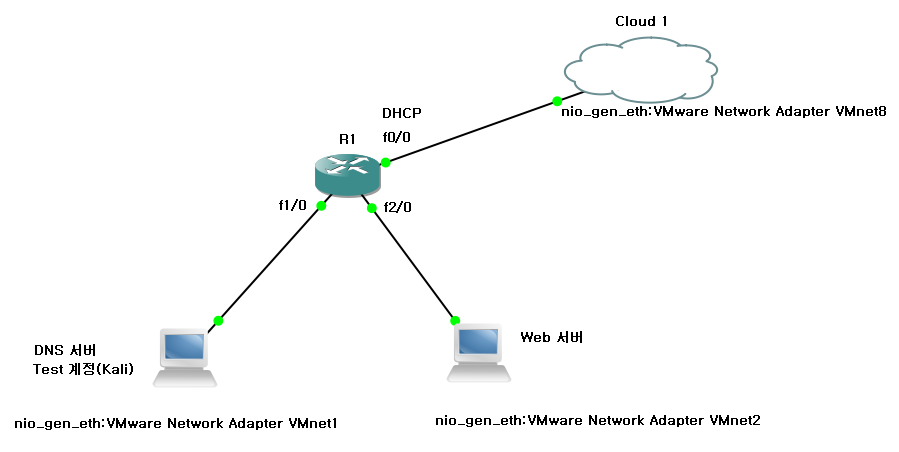
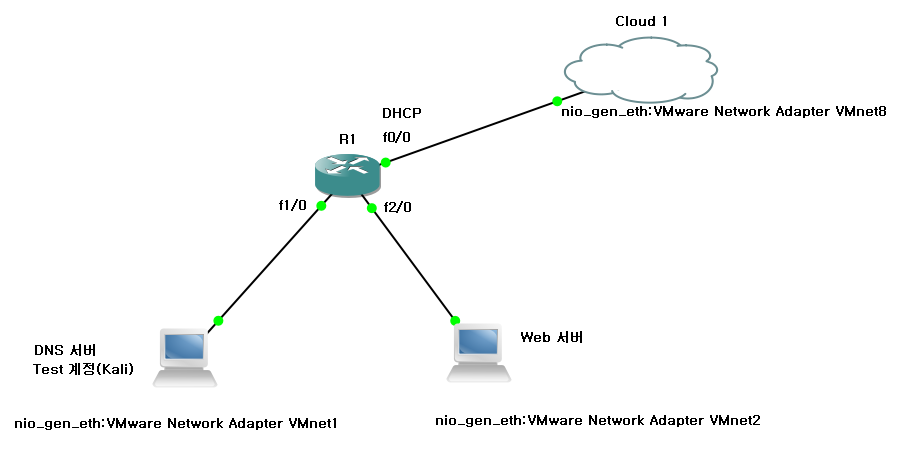
작업 환경
- VMware Workstation Pro (17.6.2 ver)
- Server
- Web 서버 : Rocky_Linux(8.10 ver, VMnet 2, PHP로 구성)
- DNS 서버 : Rocky_Linux(8.10 ver, VMnet 1)
- Client
- Kali Linux : Web 취약점 점검용 (VMnet 1)
- GNS 구성
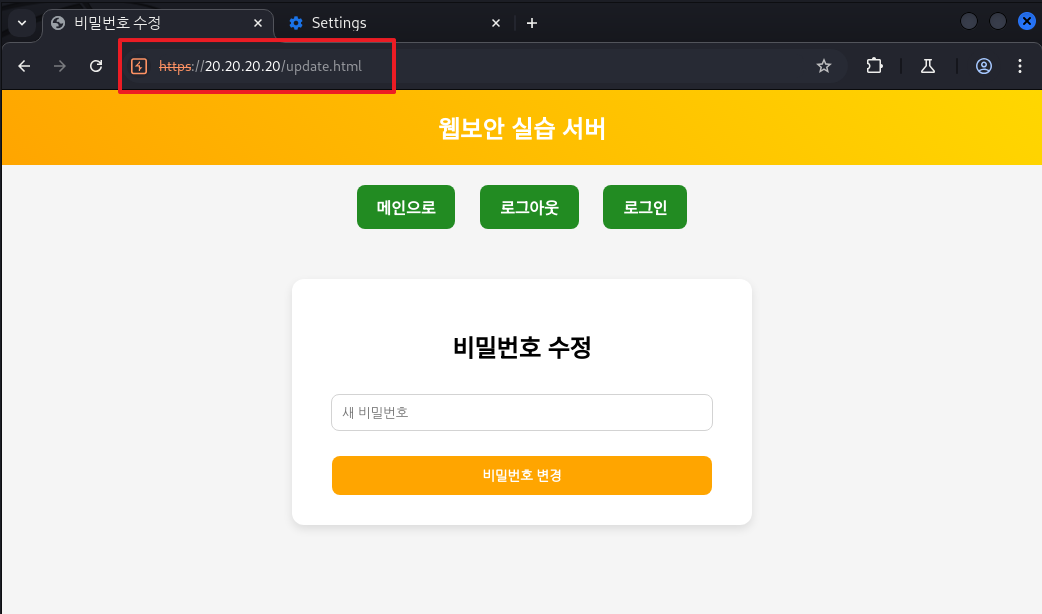
- 해당 점검은 비밀번호 수정 페이지에 한해서 진행됨
| SF (상) | 19. 세션 고정 |
| 취약점 개요 | |
| 점검 내용 | 사용자 로그인 시 항상 일정하게 고정된 세션 ID 값을 발행하는지 여부 확인 |
| 점검 목적 | 로그인할 때마다 예측 불가능한 새로운 세션 ID를 발행하여 세션 ID의 고정 사용을 방지하기 위함 |
| 보안 위협 | 사용자 로그인 시 항상 일정하게 고정된 세션 ID가 발행되는 경우 세션 ID를 도용한 비인가자의 접근 및 권한 우회가 가능 |
| 판단 기준 |
양호 : 로그인할 때마다 예측 불가능한 새로운 세션 ID가 발행되고, 기존 세션 ID는 파기될 경우 취약 : 로그인 세션 ID가 고정 사용되거나 새로운 세션 ID가 발행되지만 예측 가능한 패턴으로 발행될 경우 |
| 참고 | OWASP TOP 10 항목 중 A07 : Identification and Authentication Failures 에 해당한다고 판단 |
점검 방법
- Step 1) 로그인 시(1) 세션 ID가 발행되는지 확인하고 로그아웃 후 다시 로그인(2)할 때 예측 불가능한 새로운 세션 ID가 발급되는지 확인
아래 링크의 ②, ③ 참고
2025.05.13 - [주요정보통신기반시설가이드/Web 취약점 점검] - [SE (상)] 16. 세션 예측
[SE (상)] 16. 세션 예측
작업 환경VMware Workstation Pro (17.6.2 ver)Server Web 서버 : Rocky_Linux(8.10 ver, VMnet 2, PHP로 구성)DNS 서버 : Rocky_Linux(8.10 ver, VMnet 1)ClientKali Linux : Web 취약점 점검용 (VMnet 1)GNS 구성해당 실습은 비밀번호 수정
jijibae.tistory.com
보안 설정 방법
- 로그인할 때마다 예측 불가능한 새로운 세션 ID를 발급받도록 해야 하고 기존 세션 ID는 파기해야 함
참고
🔐 OWASP TOP 10(2021)과의 연관
OWASP TOP 10 공식 문서중 일부
"Notable CWEs included are CWE-297: Improper Validation of Certificate with Host Mismatch, CWE-287: Improper Authentication, and CWE-384: Session Fixation."
1. A07: Identification and Authentication Failures
- 사용자가 로그인한 후에도 세션 ID가 변경되지 않으면, 공격자가 미리 설정한 세션 ID를 통해 사용자의 세션을 탈취할 수 있음
'주요정보통신기반시설가이드 > Web 취약점 점검' 카테고리의 다른 글
| [PV (상)] 21. 프로세스 검증 누락 (0) | 2025.05.14 |
|---|---|
| [AU (상)] 20. 자동화 공격 (2) | 2025.05.14 |
| [SC (상)] 18. 불충분한 세션 만료 (0) | 2025.05.14 |
| [IN (상)] 17. 불충분한 인가 (0) | 2025.05.13 |
| [SE (상)] 16. 세션 예측 (0) | 2025.05.13 |