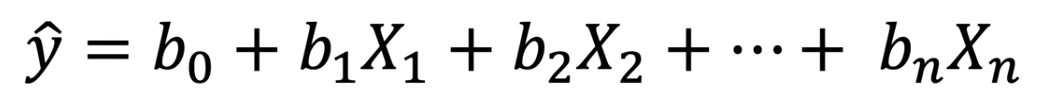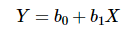Part 2-2 에서 독립변수의 개수가 1개 이상인 다중 선형 회귀 모델을 만들었다.
2023.08.29 - [ML & DL/머신러닝의 모든 것] - Part 2-2. 다중 선형 회귀 모델 만들기
Part 2-2. 다중 선형 회귀 모델 만들기
Part 2-1. 에서 독립변수의 개수가 1개인 단순 선형 회귀 모델을 만들었다. 2023.08.29 - [ML & DL/머신러닝의 모든 것] - Part 2-1. 단순 선형 회귀 모델 만들기 Part 2-1. 단순 선형 회귀 모델 만들기 Part 1에서
jijibae.tistory.com
이번에는 다항 회귀에 대해 알아보자
다항 회귀(Polynomial Regression)란?
단순 선형 회귀, 다중 선형 회귀는 선형 데이터 세트 문제에 적합한 모델이다.
이렇게 데이터 세트의 독립변수(x)와 결과(y)가 선형의 관계가 아닐 때 사용할 수 있는 모델이 다항식 회귀 모델이다.

단순 선형 회귀의 독립변수 개수는 1
다항 선형 회귀의 독립변수 개수는 >=1
다항 회귀의 독립변수의 개수는 1
단순 선형 회귀와 다항 회귀의 독립변수의 개수는 1개로 같고, 그것의 차이는 독립변수와 종속변수와의 관계가 선형인가 비선형인가의 차이이다.
다항 회귀는 위의 공식을 참고해도 알 수 있듯이 독립 변수 1개의 n제곱 형태를 가진다.
위의 차이를 명확하게 이해하면 쉽게 구현할 수 있다.
다항 회귀 구현
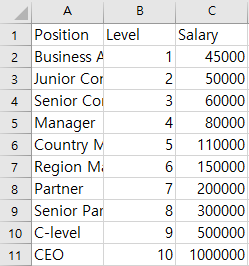
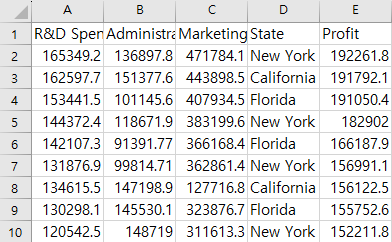
위 데이터세트는 A회사의 연차별 연봉을 조사한 것이다.
A회사에서 6.5년 근무하던 a가 B회사로 이직을 하여 과거 자신이 받았던 임금이 160,000$ 임을 감안해 똑같이 160,000$를 요구한다면 B회사 입장에서는 이것을 믿어야할까? 다항 회귀 방법을 통해 검증해보자.
<목차>
1. 라이브러리 임포트
2. 데이터세트 임포트
3. 전체 데이터세트를 사용하여 단순 선형 회귀 모델을 학습
4. 전체 데이터세트를 사용하여 다항 회귀 모델을 학습
5. 단순 선형 회귀 모델의 결과예측을 시각화하기
6. 다항 회귀 모델의 결과예측을 시각화하기
7. (6)의 결과를 더 매끄럽게 시각화하기
8. a가 거짓인지 아닌지 확인해보기
1. 라이브러리 임포트
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd2. 데이터세트 임포트
dataset = pd.read_csv('파일명')
x = dataset.iloc[:, 1:-1].values
y = dataset.iloc[:, -1].values3. 전체 데이터세트를 사용하여 단순 선형 회귀 모델을 학습
from sklearn.linear_model import LinerRegression
lin_reg = LinearRegression()
lin_reg.fit(x, y)
4. 전체 데이터세트를 사용하여 다항 회귀 모델을 학습
다항 선형 회귀를 만드는 방법은 다음과 같다.
1. n제곱된 특성들의 행렬을 만든다. (n = degree)
2. 단순 선형 회귀를 만들어서 둘의 특성을 통합하면 된다.
from sklearn.preprocessing import PolynomialFeatures
poly_reg = PolynomialFeatures(degree = 4)
x_poly = poly_reg.fit_transform(x)
lin_reg_2 = LinearRegression()
lin_reg_2.fit(x_poly, y)line1 : 사이킷런의 preprocessing 모듈에 접근해 PolynomialFeatures 클래스를 임포트한다.
전처리에 있는 이유는 x1이라는 특성을 x1^2, x1^3, ... , x1^n으로 전처리 할 것이기 때문이다.
line2 : x1^4까지 제곱된 행렬을 만들어주는 객체 생성
line3 : 기존의 특성행렬 x 를 적용시켜 제곱된 행렬의 형태로 만들어준다.
line4 : 단순 선형 회귀 모델을 하나 더 만든다.
line5 : line4 에서 만든 단순 선형 회귀 모델에 특성 값으로 제곱된 행렬을 넣어준다.
5. 단순 선형 회귀 모델의 결과예측을 시각화하기
plt.scatter(x, y, color = 'red')
plt.plot(x, lin_reg.predict(x), color = 'blue')
plt.title('Truth or Bluff(Linear Reggresion)')
plt.xlabel('Position Level')
plt.ylabel('Salary')
plt.show()line1 : scatter을 사용하여 데이터를 빨간 점으로 표현할 것이다.
line2 : 학습시킨 선형회귀 모델에 x를 입력으로 주었을 때, 나오는 예측 결과를 plot 이용해 파란색 선으로 표현할 것이다.
line3,4,5 : 제목, x축, y축 이름 설정
line6 : 출력
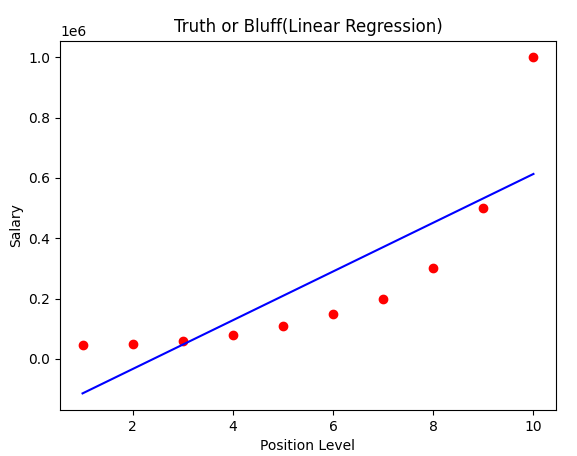
비선형의 데이터를 단순 선형 모델로 예측한 결과 회귀선이 실제 데이터와 오차가 많다.
6. 다항 회귀 모델의 결과예측을 시각화하기
plt.scatter(x, y, color = 'red')
plt.plot(x, lin_reg_2.predict(x_poly), color = 'blue')
plt.title('Truth or Bluff(polynomial Regression)')
plt.xlabel('Position Level')
plt.ylabel('Salary')
plt.show()line2 : line_reg_2를 이용할 때는 다양한 제곱으로 변환이 완료된 특정 x의 행렬에 적용해야한다.
x 자체는 단일 특성이므로 변환 없이 사용할 수가 없다.
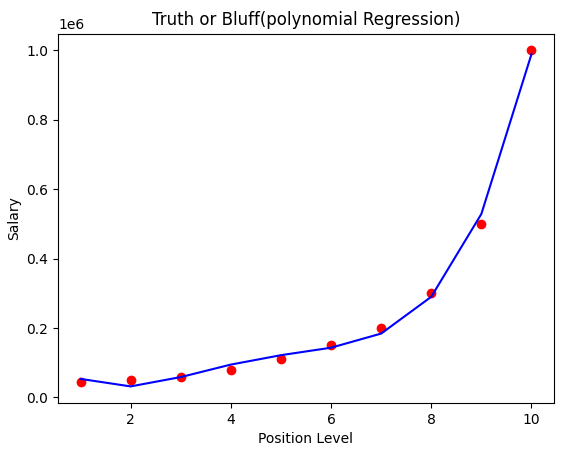
이 데이터에서는 선형 회귀보다 다항 회귀가 더 높은 정확도를 보여준다.
7. (6)의 결과를 더 매끄럽게 시각화하기
X_grid = np.arange(min(x), max(x), 0.1)
X_grid = X_grid.reshape((len(X_grid), 1))
plt.scatter(x, y, color = 'red')
plt.plot(X_grid, lin_reg_2.predict(poly_reg.fit_transform(X_grid)), color = 'blue')
plt.title('Truth or Bluff (Polynomial Regression)')
plt.xlabel('Position level')
plt.ylabel('Salary')
plt.show()x축의 범위를 더 촘촘하게(0.1간격)으로 나눠서 회귀선을 표시하면 더 매끄러워진다.
numpy의 arange 함수를 이용한다.
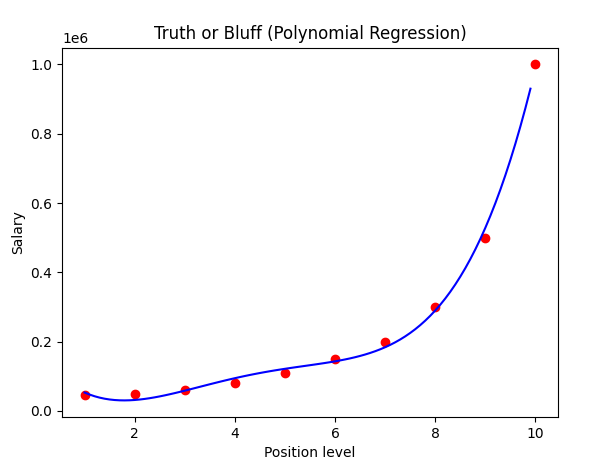
회귀선이 보기좋게 매끄러워 졌다.
8. a가 거짓인지 아닌지 확인해보기
우리가 이러한 작업을 한 이유는 새로운 고용자 a가 전 직장에서 받는 임금이 맞는지를 알기 위해 했으므로,
그의 말이 맞는지 확인해보자.
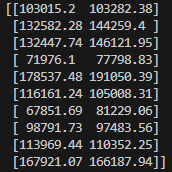
print(lin_reg_2([[6.5]]))=>[158862.45265155] 로 160,000$를 받았다는 a의 말이 맞을 수 있다는 결론이 나온다.
'🤖 AI > 머신러닝의 모든 것' 카테고리의 다른 글
| Part 2-2. 다중 선형 회귀(Multiple Linear Regression)의 이해와 구현 (0) | 2023.08.29 |
|---|---|
| Part 2-1. 단순 선형 회귀(Simple Linear Regression)의 이해와 구현 (0) | 2023.08.29 |
| Part 1. 데이터 전처리 (0) | 2023.08.25 |