
이제 본격적으로 연합학습을 공부하기 전, 자주 나오는 용어들을 정리하고자 한다.
공부를 시작하는 초기 단계라서 이해하기 어려운 내용 + 논문 출처는 나중에 다시 추가할 예정
헷갈리는 개념이라 이번 기회에 이해가 잘 되도록 정리해야겠다.
틀린 부분이 있다면 댓글로 알려주세요. 감사히 생각하겠습니다.
Non-IID 란?
우선, 연합학습은 모델을 학습하는 여러가지 방법 중 하나의 방법으로 연합학습에 참여하는 각 클라이언트들은 자신의 로컬 데이터를 서버에 전송하지 않고, 자신의 로컬 영역에서 로컬 데이터를 기반으로 모델을 학습한다. 일반적인 경우, 학습의 대상이 되는 데이터들은 클라이언트마다 다른 것이 자명하고 이것을 Non-IID(Independent and Identically Distributed) Data 라고 한다.
IID는 확률 및 통계의 용어로서 확률변수 집합이 서로 독립적이고, 동일한 확률분포를 가질 때를 의미한다.
즉, Non-IID라는 것은 반대로 분산된 각 클라이언트가 가지고 있는 데이터가 서로 매우 다른 성격이고, 불균형한 확률분포를 가진다는 것을 의미한다. 연합학습에서는 서로 이질적인(Heterogeneous) 데이터를 학습하기 위한 가정을 가지고 수행된다.
Non-IID 이해를 위한 간단한 예시
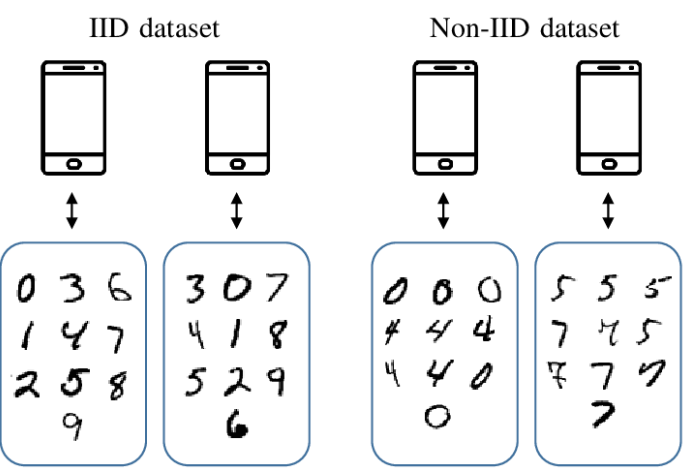
위의 사진은 AI를 공부하는 모두가 아는 MNIST의 손글씨 Dataset이다.
왼쪽의 각 클라이언트들의 dataset은 정확한 숫자의 모양은 달라도 확률변수 집합이 서로 독립적이고, 숫자 0~9를1개씩 가지는 동일한 확률 분포를 가진다. -> IID dataset
반대로 오른쪽의 각 클라이언트들의 dataset은 확률변수 집합이 비독립/독립 적일지는 몰라도, 숫자 0~9를 균등하게 가지지 않는 불균형한 확률분포를 가진다. -> Non-IID dataset
문제점 및 과제
대부분의 경우 각 클라이언트의 데이터는 Non-IID 할 것이다. 만일 Non-IID Dataset으로 모델을 학습하게 되면 모델 정확도도 낮아지고, 균일하지 않고 많기만한 Data에 Network cost도 높아질 것이다.
이를 해결하기 위해 학습에 참여하는 클라이언트 선택하는 방법, 데이터셋 증류(Dataset distillation) 등 다양한 방법들이 연구되고 있다.