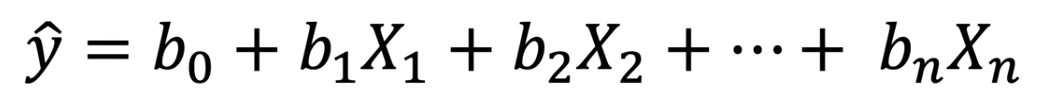공부를 시작하는 초기 단계라서 이해하기 어려운 내용 + 논문 출처는 나중에 다시 추가할 예정
헷갈리는 개념이라 이번 기회에 이해가 잘 되도록 정리해야겠다.
틀린 부분이 있다면 댓글로 알려주세요. 감사히 생각하겠습니다.
Non-IID 란?
우선, 연합학습은 모델을 학습하는 여러가지 방법 중 하나의 방법으로 연합학습에 참여하는 각 클라이언트들은 자신의 로컬 데이터를 서버에 전송하지 않고, 자신의 로컬 영역에서 로컬 데이터를 기반으로 모델을 학습한다. 일반적인 경우, 학습의 대상이 되는 데이터들은 클라이언트마다 다른 것이 자명하고 이것을 Non-IID(Independent and Identically Distributed) Data 라고 한다.
IID는 확률 및 통계의 용어로서 확률변수 집합이 서로 독립적이고, 동일한 확률분포를 가질 때를 의미한다.
즉, Non-IID라는 것은 반대로 분산된 각 클라이언트가 가지고 있는 데이터가 서로 매우 다른 성격이고, 불균형한 확률분포를 가진다는 것을 의미한다. 연합학습에서는 서로 이질적인(Heterogeneous) 데이터를 학습하기 위한 가정을 가지고 수행된다.
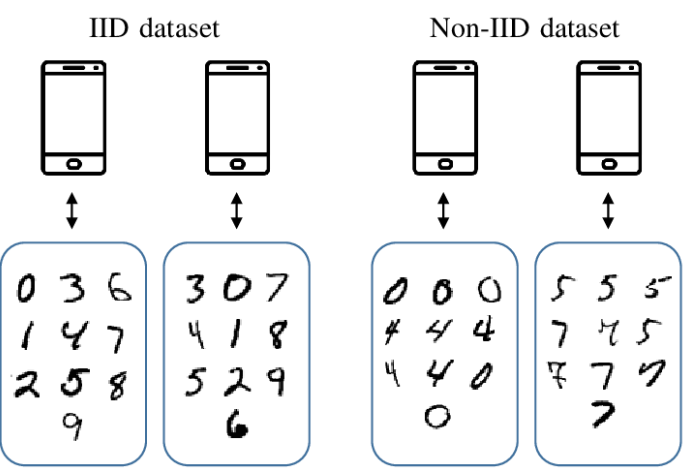
Non-IID 이해를 위한 간단한 예시
그림 출처 : https://www.researchgate.net/publication/344017123_Wireless_for_Machine_Learning?_tp=eyJjb250ZXh0Ijp7ImZpcnN0UGFnZSI6Il9kaXJlY3QiLCJwYWdlIjoiX2RpcmVjdCJ9fQ
위의 사진은 AI를 공부하는 모두가 아는 MNIST의 손글씨 Dataset이다.
왼쪽의 각 클라이언트들의 dataset은 정확한 숫자의 모양은 달라도 확률변수 집합이 서로 독립적이고, 숫자 0~9를1개씩 가지는 동일한 확률 분포를 가진다. -> IID dataset
반대로 오른쪽의 각 클라이언트들의 dataset은 확률변수 집합이 비독립/독립 적일지는 몰라도, 숫자 0~9를 균등하게 가지지 않는 불균형한 확률분포를 가진다. -> Non-IID dataset
문제점 및 과제
대부분의 경우 각 클라이언트의 데이터는 Non-IID 할 것이다. 만일 Non-IID Dataset으로 모델을 학습하게 되면 모델 정확도도 낮아지고, 균일하지 않고 많기만한 Data에 Network cost도 높아질 것이다.
이를 해결하기 위해 학습에 참여하는 클라이언트 선택하는 방법, 데이터셋 증류(Dataset distillation) 등 다양한 방법들이 연구되고 있다.
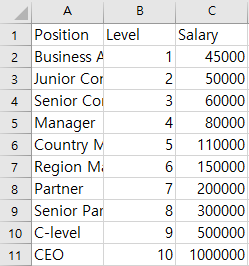
전처리에 있는 이유는 x1이라는 특성을 x1^2, x1^3, ... , x1^n으로 전처리 할 것이기 때문이다.
line2 : x1^4까지 제곱된 행렬을 만들어주는 객체 생성
line3 : 기존의 특성행렬 x 를 적용시켜 제곱된 행렬의 형태로 만들어준다.
line4 : 단순 선형 회귀 모델을 하나 더 만든다.
line5 : line4 에서 만든 단순 선형 회귀 모델에 특성 값으로 제곱된 행렬을 넣어준다.
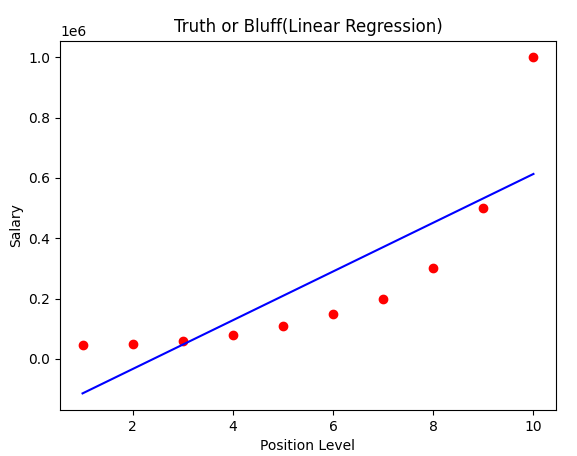
5. 단순 선형 회귀 모델의 결과예측을 시각화하기
plt.scatter(x, y, color = 'red')
plt.plot(x, lin_reg.predict(x), color = 'blue')
plt.title('Truth or Bluff(Linear Reggresion)')
plt.xlabel('Position Level')
plt.ylabel('Salary')
plt.show()
line1 : scatter을 사용하여 데이터를 빨간 점으로 표현할 것이다.
line2 : 학습시킨 선형회귀 모델에 x를 입력으로 주었을 때, 나오는 예측 결과를 plot 이용해 파란색 선으로 표현할 것이다.
line3,4,5 : 제목, x축, y축 이름 설정
line6 : 출력
비선형의 데이터를 단순 선형 모델로 예측한 결과 회귀선이 실제 데이터와 오차가 많다.
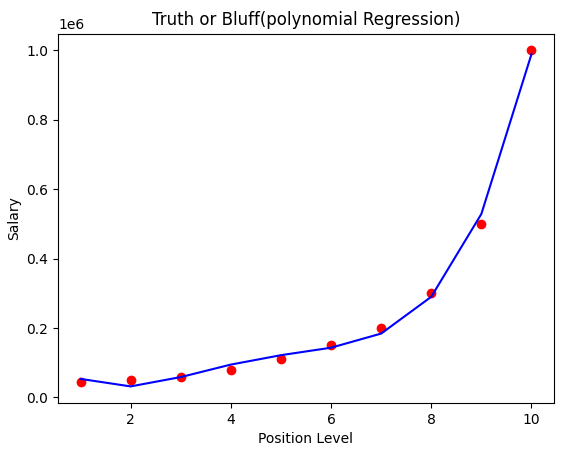
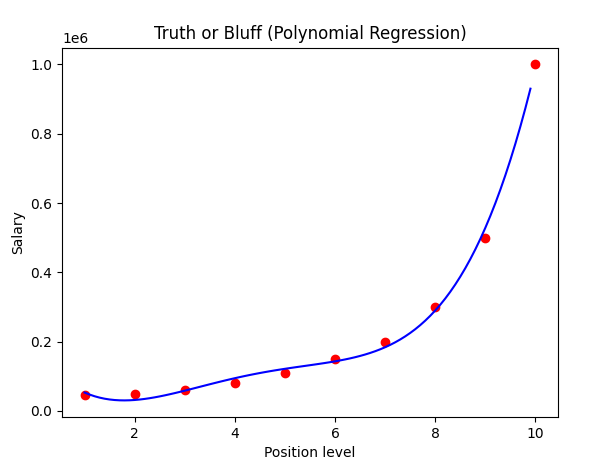
6. 다항 회귀 모델의 결과예측을 시각화하기
plt.scatter(x, y, color = 'red')
plt.plot(x, lin_reg_2.predict(x_poly), color = 'blue')
plt.title('Truth or Bluff(polynomial Regression)')
plt.xlabel('Position Level')
plt.ylabel('Salary')
plt.show()
line2 : line_reg_2를 이용할 때는 다양한 제곱으로 변환이 완료된 특정 x의 행렬에 적용해야한다.
x 자체는 단일 특성이므로 변환 없이 사용할 수가 없다.
이 데이터에서는 선형 회귀보다 다항 회귀가 더 높은 정확도를 보여준다.
7. (6)의 결과를 더 매끄럽게 시각화하기
X_grid = np.arange(min(x), max(x), 0.1)
X_grid = X_grid.reshape((len(X_grid), 1))
plt.scatter(x, y, color = 'red')
plt.plot(X_grid, lin_reg_2.predict(poly_reg.fit_transform(X_grid)), color = 'blue')
plt.title('Truth or Bluff (Polynomial Regression)')
plt.xlabel('Position level')
plt.ylabel('Salary')
plt.show()
x축의 범위를 더 촘촘하게(0.1간격)으로 나눠서 회귀선을 표시하면 더 매끄러워진다.
numpy의 arange 함수를 이용한다.
회귀선이 보기좋게 매끄러워 졌다.
8. a가 거짓인지 아닌지 확인해보기
우리가 이러한 작업을 한 이유는 새로운 고용자 a가 전 직장에서 받는 임금이 맞는지를 알기 위해 했으므로,
그의 말이 맞는지 확인해보자.
print(lin_reg_2([[6.5]]))
=>[158862.45265155] 로 160,000$를 받았다는 a의 말이 맞을 수 있다는 결론이 나온다.