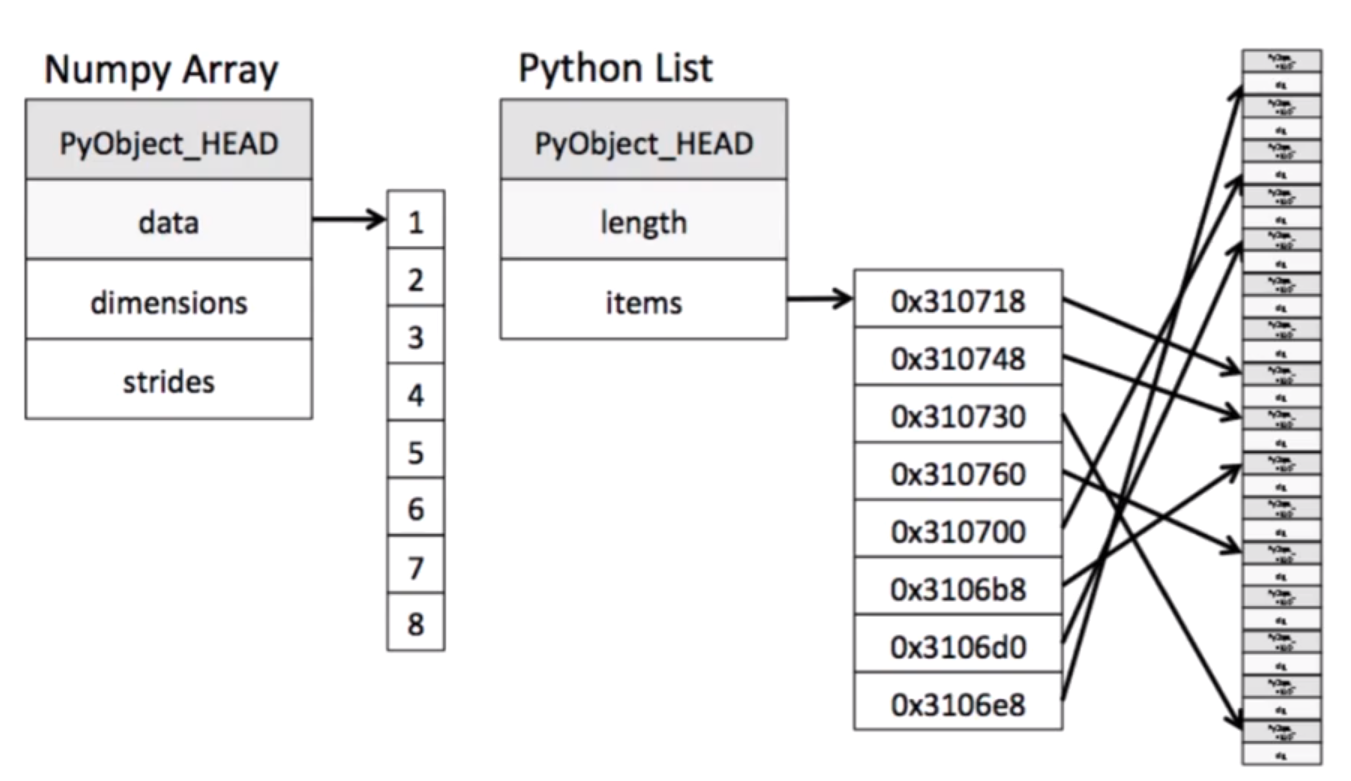
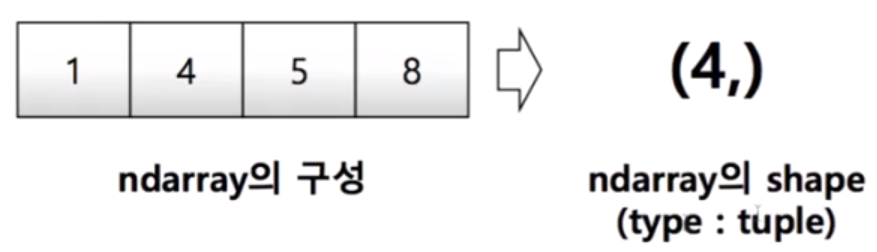
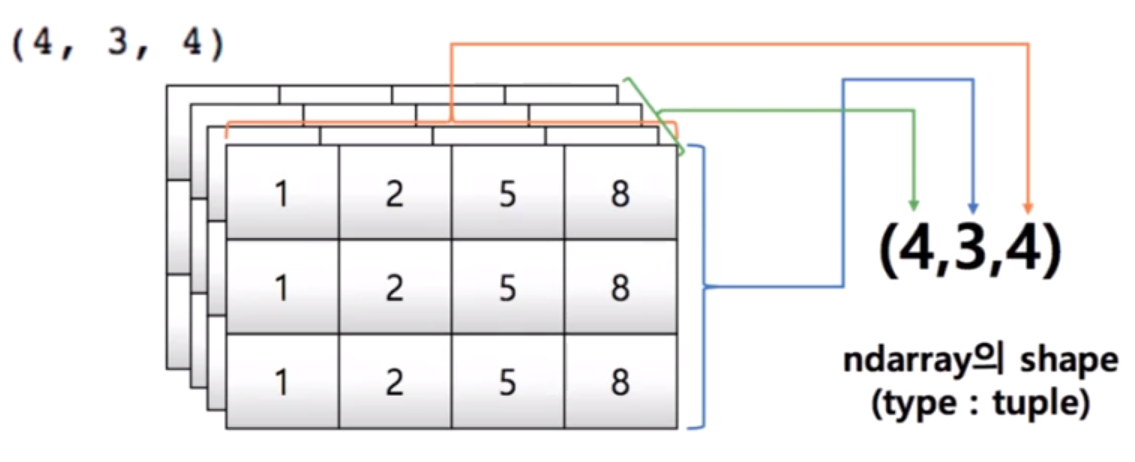
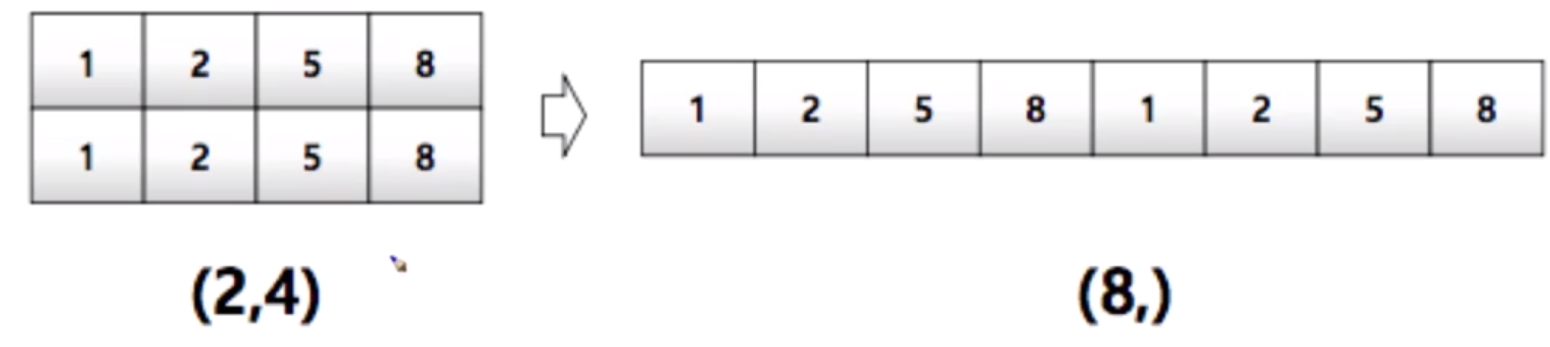
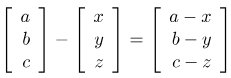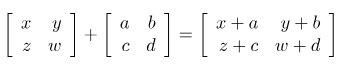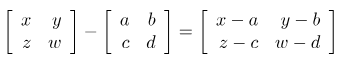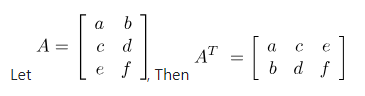import numpy as np
test_array = np.array([1, 4, 5, 8], float) # 데이터 타입 지정
print(test_array)
print(type(test_array[3]))
[1. 4. 5. 8.]
numpy.float64
2. Array Shape
shape : numpy array의 dimension 구성을 반환함
dtype : numpy array의 데이터 type을 반환함
ndim : numer of dimension
size : data의 개수
import numpy as np
test_array = np.array([1,4,5,"8"], float) #Sring Type의 데이터를 입력해도
print(test_array)
print(type(test_array[3])) # Float Type으로 자동 형변환 실시
print(test_array.dtype) # Array(배열) 전체의 데이터 Type을 반환함
print(test_array.shape) # Array(배열) 의 shape을 반환함
print(np.array(test_array, int).ndim) # numer of dimension
print(np.array(test_array, int).size) # 총 data의 개수
vector 간 덧셈 또는 뺄셈 연산을 할 때, 연산이 가능한 사이즈인지를 확인하여 가능 여부를 True 또는 False로 반환
def vector_size_check(*vector_variables):
return all(len(vector_variables[0]) == x
for x in [len(vector) for vector in vector_variables[1:]])
# 실행결과
print(vector_size_check([1,2,3], [2,3,4], [5,6,7]))
print(vector_size_check([1, 3], [2,4], [6,7]))
print(vector_size_check([1, 3, 4], [4], [6,7]))
True
Ture
Flase
2. Vector Addition
vector간 덧셈을 실행하여 결과를 반환함, 단 입력되는 vector의 갯수와 크기는 일정하지 않음
def vector_addition(*vector_variables):
if vector_size_check(*vector_variables) == False:
raise ArithmeticError
return [sum(element) for element in zip(*vector_variables)]
# 실행결과
print(vector_addition([1, 3], [2, 4], [6, 7]))
print(vector_addition([1, 5], [10, 4], [4, 7]))
print(vector_addition([1, 3, 4], [4], [6,7]))
[9, 14] [15, 16]
ArithmeticError
3. Vector Substraction
vector간 뺄셈을 실행하여 결과를 반환함, 단 입력되는 vector의 갯수와 크기는 일정하지 않음
def vector_subtraction(*vector_variables):
if vector_size_check(*vector_variables) == False:
raise ArithmeticError
return [2 * elements[0] - sum(elements) for element in zip(*vector_variables)]
# 실행결과
print(vector_subtraction([1, 3], [2, 4]))
print(vector_subtraction([1, 5], [10, 4], [4, 7]))
[-1, -1] [-13, -6]
4. Scalar Vector Product
하나의 scalar 값을 vector에 곱함, 단 입력되는 vector의 크기는 일정하지 않음
def scalar_vector_product(alpha, *vector_variables):
return [alpha * row for row in vector_variables]
# 실행결과
print (scalar_vector_product(5,[1,2,3])
print (scalar_vector_product(3,[2,2]))
print (scalar_vector_product(4,[1]))
[5, 10, 15] [6, 6] [4]
5. Matrix Size Check
matrix 간 덧셈 또는 뺄셈 연산을 할 때, 연산이 가능한 사이즈인지를 확인하여 가능 여부를 True 또는 False로 반환함
비교가 되는 n개의 matrix가 서로 동치인지 확인하여 True 또는 False를 반환함
all( ) 이 두 번인 이유 : matrix 형태이므로 row의 값이 다 같은지 확인하고, column이 모두 같은지도 확인
def is_matrix_equal(*matrix_variables):
all([all([len(set(row)) == 1 for row in zip(*matrix)]) for matrix in zip(*matrix_variables)])
# 실행결과
matrix_x = [[2, 2], [2, 2]]
matrix_y = [[2, 5], [2, 1]]
print (is_matrix_equal(matrix_x, matrix_y, matrix_y, matrix_y))
print (is_matrix_equal(matrix_x, matrix_x))
False
True
7. Matrix Addition
matrix간 덧셈을 실행하여 결과를 반환함, 단 입력되는 matrix의 갯수와 크기는 일정하지 않음
def matrix_addition(*matrix_variables):
if matrix_size_check(*matrix_variables) == False:
raise ArithmeticError
return [[sum(row) for row in zip(*matrix)] for matrix in zip(*matrix_variables)]
# 실행결과
matrix_x = [[2, 2], [2, 2]]
matrix_y = [[2, 5], [2, 1]]
matrix_z = [[2, 4], [5, 3]]
print (matrix_addition(matrix_x, matrix_y))
print (matrix_addition(matrix_x, matrix_y, matrix_z))
[[4, 7], [4, 3]]
[[6, 11], [9, 6]]
8. Matrix Subtraction
matrix간 뺄셈을 실행하여 결과를 반환함, 단 입력되는 matrix의 갯수와 크기는 일정하지 않음
def matrix_subtraction(*matrix_variables):
if matrix_size_check(*matrix_variables) == False:
raise ArithmeticError
return [[2 * row[0] - sum(row) for row in zip(*matrix)] for matrix in zip(*matrix_variables)]
# 실행결과
matrix_x = [[2, 2], [2, 2]]
matrix_y = [[2, 5], [2, 1]]
matrix_z = [[2, 4], [5, 3]]
print(matrix_subtraction(matrix_x, matrix_y))
print(matrix_subtraction(matrix_x, matrix_y, matrix_z))
[[0, -3], [0, 1]]
[[-2, -7], [-5, -2]]
9. Matrix Transpose
matrix의 역행렬을 구하여 결과를 반환함, 단 입력되는 matrix의 크기는 일정하지 않음
def matrix_transpose(*matrix_variables):
return [[element for element in row] for row in zip(*matrix_variables)]]
# 실행결과
matrix_w = [[2, 5], [1, 1], [2, 2]]
print(matrix_transpose(matrix_w))
[[2, 1, 2], [5, 1, 2]]
10. Scalar Matrix Product
하나의 scalar 값을 matrix에 곱함, 단 입력되는 matrix의 크기는 일정하지 않음
def scalar_matrix_product(alpha, matrix_variable):
return [[alpha * element for element in row] for row in matrix_x]
# 실행결과
matrix_x = [[2, 2], [2, 2], [2, 2]]
matrix_y = [[2, 5], [2, 1]]
matrix_z = [[2, 4], [5, 3]]
matrix_w = [[2, 5], [1, 1], [2, 2]]
print(scalar_matrix_product(3, matrix_x))
print(scalar_matrix_product(2, matrix_y))
print(scalar_matrix_product(4, matrix_z))
print(scalar_matrix_product(3, matrix_w))
다른 패키지 없이 Python 만을 사용하여 한 뉴스에 대해 비슷한 뉴스를 찾아내는 News Categorization을 진행하려 한다.
진행 하기 앞서 알아야하는 것이 있다.
컴퓨터는 문자를 그대로 이해하지 못함
문자 -> 숫자
숫자간에 유사하다는 표현을 어떻게 할까?
유사하다 = 가깝다(거리 계산) - 유클리드 or Cosine distance
따라서
문자 -> 숫자 -> Vector
문자를 Vector로 바꿔주는 One-Hot Encoding 사용!
One-Hot Encoding
Vector Space를 만들어 하나의 문자에 대한 Vector 표현을 가능하게 해준다.
하나의 문자(단어)를 Vector의 index로 인식, 단어 존재시 1 없으면 0
One-Hot EncodingBag of words
News Categorization Process
파일을 불러오기 (80개의 기사를 스크럽한 txt 파일)
파일을 읽기
단어사전(corpus) 만들기, 단어별 Index 만들기
만들어진 인덱스로 문서별 Bag of words vector 생성
비교하고자 하는 문서 비교하기
얼마나 맞는지 측정하기
1. 파일을 불러오기
import os
def get_file_list(dir_name):
return os.listdir(dir_name) # listdir 이라는 Python bulit-in module 사용
if __name__ == "__main__":
dir_name = "news_data"
file_list = get_file_list(dir_name)
file_list = [os.path.join(dir_name, file_name) for file_name in file_list]
get_file_list : news_data 에 해당하는 폴더 내의 파일 명을 모두 가져와서 return 해주는 함수
os.path.join : Python에서 폴더-파일명을 연결을 해줄 때, 각 os별로 폴더 구분 방법이 다르므로 os에 맞게 자동으로 설정해줌
2. 파일별로 내용 읽기
def get_contents(file_list):
y_class = []
X_text = []
class_dict = {
1:"0", 2:"0", 3:"0", 4:"0", 5:"1", 6:"1", 7:"1", 8:"1"} # 0 = 야구, 1 = 축구
for file_name in file_list:
try:
f = open(file_name, "r", encoding="cp949") # 수집경로 windows -> cp949, Linux&Mac -> UTF
category = int(file_name.split(os.sep)[1].split("_")[0])
y_class.append(class_dict[category])
X_text.append(f.read())
f.close()
expect UnicodeDecodeError as e:
print(e)
print(file_name)
return X_text, y_class
os.sep : 파일 폴더 기호(\)를 나누는 것을 의미. os.sep[1] = only 파일명 이 작업은 ->방향으로 수행된다.
(파일명 예시 : 1_Dae-Ho Lee walk-off homer gives Mariners 4-2 win over Rangers)
X_text 에는 문서 내용이, y_class 에는 카테고리의 값들이 있다.
3. Corpus + 단어별 index 만들기
def get_cleaned_text(word):
import re
p_word = re.sub('\W+','', text.lower())
return p_word
def get_corpus_dict(text):
text = [sentence.split() for sentence in text] # text -> 2-Dimensional List
cleaned_words = [get_cleaned_text(word) for words in text for word in words] # 1-Dimensional List
from collections import Ordereddict
corpus_dict = OrderedDict()
for i, v in enumerate(set(cleaned_words)):
corpus_dict[v] = i
return corpus_dict
re : regular expression
courpus_dict[v] : 동일한 단어들이 없으므로(set) 단어가 key 값이 될 수 있다.
4. 문서별 Bag of words vector 생성
def get_count_vector(text, corpus):
text = [word.split() for word in text]
word_number_list = [[corpus[get_cleaned_text(word)] for word in words] for words in text]
X_vector = [[0 for _ in range(len(corpus))] for _ in range(len(text))] # Vector 초기화
for i, text in enumerate(word_number_list):
for word_number in text:
X_vector[i][word_number] += 1
return X_vector
word_number_list 는 80개의 기사로 이루어진 2-Dimensional List이고, 해당 단어의 value 값을 가짐
5.비교하기
import math
def get_cosine_sililarity(v1, v2):
"compute cosine similarity of v1 to v2: (v1 dot v2) / {||v1|| * ||v2||)"
sumxx, sumxy, sumyy = 0, 0, 0
for i in range(len(v1)):
x = v1[i]; y = v2[i]
sumxx += x*x
sumxy += x*y
sumyy += y*y
return sumxy/math.sqrt(sumxx*sumyy)
단순 cosine distance 공식을 구현한 것
6.비교결과 정리하기
# source : 대상 문서
def get_similarity_score(X_vector, source):
source_vector = X_vector[source]
similarity_list = []
for target_vector in X_vector:
similarity_list.append(
get_cosine_similarity(source_vector, target_vector))
return similarity_list
def get_top_n_similarity_news(similarity_score, n):
import operator
x = {i:v for i, v in enumerate(similarity_score)}
sorted_x = sorted(x.items), key=operator.itemgetter(1))
return list(reversed(sorted_x))[1:n+1]
get_cosine_similarity : 총 80번 반복하고, source 의 경우 값이 1이므로, 1인 것은 제외한다.
OrderedDict 자료형이므로 sorted가 가능하다.
전체코드
import os
def get_file_list(dir_name):
return os.listdir(dir_name) # listdir 이라는 Python bulit-in module 사용
def get_contents(file_list):
y_class = []
X_text = []
class_dict = {
1:"0", 2:"0", 3:"0", 4:"0", 5:"1", 6:"1", 7:"1", 8:"1"} # 0 = 야구, 1 = 축구
for file_name in file_list:
try:
f = open(file_name, "r", encoding="cp949") # 수집경로 windows -> cp949, Linux&Mac -> UTF
category = int(file_name.split(os.sep)[1].split("_")[0])
y_class.append(class_dict[category])
X_text.append(f.read())
f.close()
except UnicodeDecodeError as e:
print(e)
print(file_name)
return X_text, y_class
def get_cleaned_text(word):
import re
p_word = re.sub('\W+','', word.lower())
return p_word
def get_corpus_dict(text):
text = [sentence.split() for sentence in text] # text -> 2-Dimensional List
cleaned_words = [get_cleaned_text(word) for words in text for word in words] # 1-Dimensional List
from collections import OrderedDict
corpus_dict = OrderedDict()
for i, v in enumerate(set(cleaned_words)):
corpus_dict[v] = i
return corpus_dict
def get_count_vector(text, corpus):
text = [word.split() for word in text]
word_number_list = [[corpus[get_cleaned_text(word)] for word in words] for words in text]
X_vector = [[0 for _ in range(len(corpus))] for _ in range(len(text))] # Vector 초기화
for i, text in enumerate(word_number_list):
for word_number in text:
X_vector[i][word_number] += 1
return X_vector
import math
def get_cosine_similarity(v1, v2):
"compute cosine similarity of v1 to v2: (v1 dot v2) / {||v1|| * ||v2||)"
sumxx, sumxy, sumyy = 0, 0, 0
for i in range(len(v1)):
x = v1[i]; y = v2[i]
sumxx += x*x
sumxy += x*y
sumyy += y*y
return sumxy/math.sqrt(sumxx*sumyy)
# source : 대상 문서
def get_similarity_score(X_vector, source):
source_vector = X_vector[source]
similarity_list = []
for target_vector in X_vector:
similarity_list.append(
get_cosine_similarity(source_vector, target_vector))
return similarity_list
def get_top_n_similarity_news(similarity_score, n):
import operator
x = {i:v for i, v in enumerate(similarity_score)}
sorted_x = sorted(x.items(), key=operator.itemgetter(1))
return list(reversed(sorted_x))[1:n+1]
def get_accuracy(similarity_list, y_class, source_news):
source_class = y_class[source_news]
return sum([source_class == y_class[i[0]] for i in similarity_list]) / len(similarity_list)
if __name__ == "__main__":
dir_name = "news_data"
file_list = get_file_list(dir_name)
file_list = [os.path.join(dir_name, file_name) for file_name in file_list]
X_text, y_class = get_contents(file_list)
corpus = get_corpus_dict(X_text)
print("Number of words : {0}".format(len(corpus)))
X_vector = get_count_vector(X_text, corpus)
source_number = 10
result = []
for i in range(80):
source_number = i
similarity_score = get_similarity_score(X_vector, source_number)
similarity_news = get_top_n_similarity_news(similarity_score, 10)
#print(similarity_news)
accuracy_score = get_accuracy(similarity_news, y_class, source_number)
result.append(accuracy_score)
print(sum(result) / 80)
마치며
사실 이렇게 잘 안한다. . .
이미 만들어진 모듈을 사용하지. . .
모듈을 사용할 때, 어떻게 작동하지?? 라는 기술적 부채를 덜기위해 low level에서 진행해 보았다.
matrix_a = [[3, 6], [4, 5]]
matrix_b = [[5, 8], [6, 7]]
result = [[sum(row) for row in zip(*t)] for t in zip(matrix_a, matrix_b)]
print(result)
[[8,14], [10, 12]]
2. Matrix 곱셈(Scalar)
Ex) Scalar-Matrix Product
matrix_a = [[3,6], [4,5]]
alpha = 4
result = [[alpha * element for element in t] for t in matrix_a]
print(result)
[[12, 24], [16, 20]]
3. Matrix Transpose
Ex) List comprehension + zip
matrix_a = [[1, 2, 3], [4, 5, 6]]
result = [[row for row in t] for t in zip(*matrix_a)]
print(result)
4. Matrix Product
Ex) matrix_b에서 zip(*matrix_b)을 사용하여 column_b을 만들어줌
matrix_a = [[1, 2, 3], [4, 5, 6]]
matrix_b = [[1, 4], [2, 5], [3, 6]]
result = [[a * b for a, b in zip(row_a, column_b) for column_b in zip(*matrix_b)] for row_a in matrix_a]
print(result)